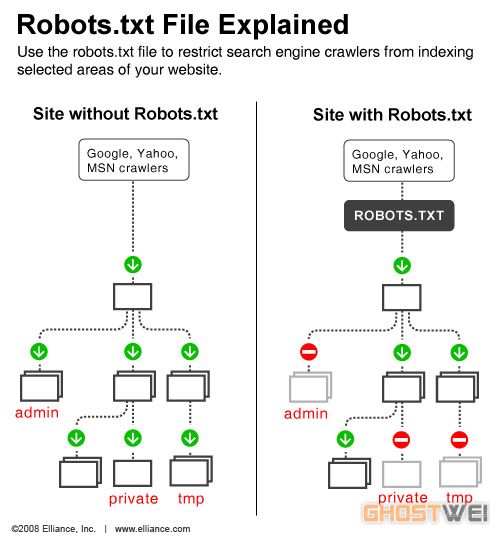
robots.txt是一种存放于网站根目录下的文本文件,用于告诉搜索引擎的爬虫(spider),此网站中的哪些内容是不应被搜索引擎的索引,哪些是可以被索引。通常认为,robots.txt文件用来搜索引擎对目标网页的抓取。
robots.txt协议并不是一个规范,而只是约定俗成的,通常搜索引擎会识别这个文件,但也有一些特殊情况。
对于Google来说,使用robots也未必能阻止Google将网址编入索引,如果有其他网站链接到该网页的话,Google依然有可能会对其进行索引。按照Google的说法,要想彻底阻止网页的内容在Google网页索引中(即使有其他网站链接到该网页)出现,需要使用noindex元标记或x-robots-tag。例如将下面的一行加入到网页的header部分。
<meta name="googlebot" content="noindex">
如果Google看到某一页上有noindex的元标记,就会将此页从Google的搜索结果中完全丢弃,而不管是否还有其他页链接到此页。

对于百度来说,情况和Google类似,如果有其他网站链接目标网页,也有可能会被百度收录,从百度的说明页面上看,百度并不支持像Google那样通过noindex完全将网页从索引上删除,只支持使用noarchive元标记来禁止百度显示网页快照。具体的语句如下。
上面这个标记只是禁止百度显示该网页的快照,百度会继续为网页建索引,并在搜索结果中显示网页摘要。
例如,淘宝网目前就通过robots.txt来屏蔽百度爬虫,但百度依旧收录了淘宝网的内容,百度搜索“淘宝网”,第一个结果也是淘宝网首页地址,只是该页面没有网页快照,因此看来,网站只能禁止百度的快照,而无法禁止百度为网页建索引。


该页面还没有任何评论,赶快占个沙发吧!